论文链接:https://arxiv.org/pdf/2512.24601
代码链接:https://github.com/alexzhang13/rlm
摘要
我们从推理时扩展的角度研究如何使大语言模型(LLM)能够处理任意长度的提示。我们提出了一种 Recursive Language Models (RLMs),这是一种通用的推理范式,它将长提示视为外部环境的一部分,并允许 LLM 以编程方式检查、分解提示片段,并递归调用自身。我们发现,RLM 能够成功处理超出模型上下文窗口两个数量级的输入,即使对于较短的提示,在四个不同的长上下文任务中,其性能也显著优于传统的前沿 LLM 和常见的长上下文支架,而成本却相当。在小规模实验中,我们对第一个原生递归语言模型进行了后训练。我们的模型 RLM-Qwen3-8B 的性能平均比底层 Qwen3-8B 模型高出 28.3%,甚至在三个长上下文任务中接近了传统 GPT-5 的性能。代码可在 https://github.com/alexzhang13/rlm 获取。
1.Introduction
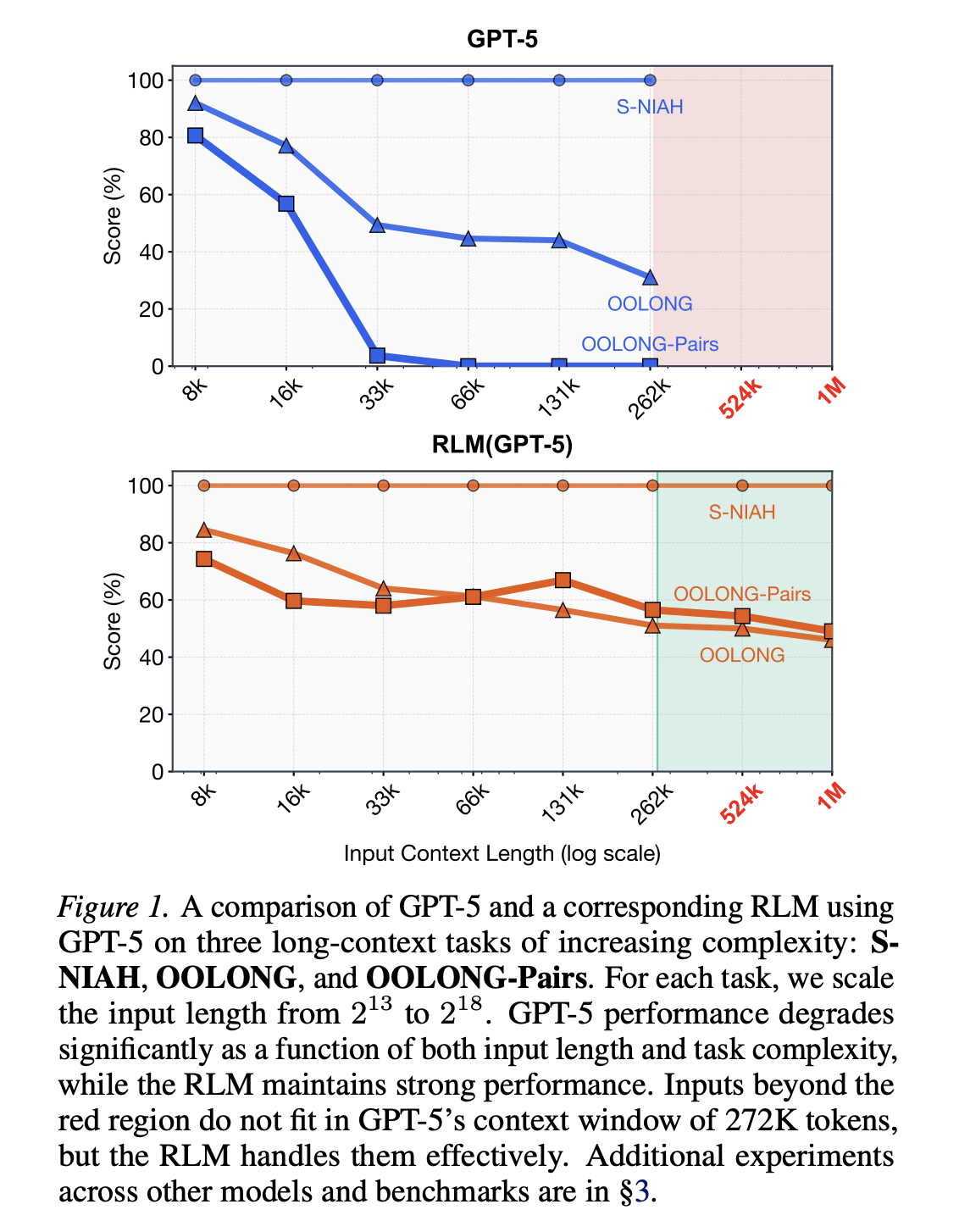
前沿推理模型的上下文窗口有限,即使在其限制范围内,也容易出现上下文衰减现象。如图 1 所示,随着提示信息长度的增加,推理质量急剧下降。尽管我们预期通过改进训练、架构和基础设施,上下文长度会稳步增长,但我们更感兴趣的是,是否有可能将通用 LLM 的上下文规模扩大几个数量级。随着 LLM 开始被广泛应用于长周期任务,这个问题变得日益紧迫,因为在这些任务中,它们必须例行处理数千万甚至数亿个 token。
我们从扩展推理时计算的角度来研究这个问题。推理模型已成为 LLM 的基本接口,这不仅带来了经验上的提升,而且与传统的 Transformer 模型相比,也带来了更强的理论表达能力,这给了我们很大的启发。虽然大多数处理长上下文的推理时间方法都针对特定任务,但最流行的通用方法是上下文压缩或浓缩,即一旦上下文长度超过阈值,就对来自用户请求或 Agent 轨迹的上下文进行重复总结。然而,对于需要密集访问整个提示信息的任务来说,压缩方法的表达能力往往不足。它假定提示信息早期出现的一些细节可以被安全地忽略,以便为新内容腾出空间。
我们引入了 Recursive Language Models (RLMs),这是一种通用的推理范式,能够显著扩展 LLM 的有效输入和输出长度。其核心思想是,任意长度的用户提示不应直接输入到神经网络(例如Transformer)中,而应被视为LLM需要与之进行符号化和递归交互的环境的一部分。
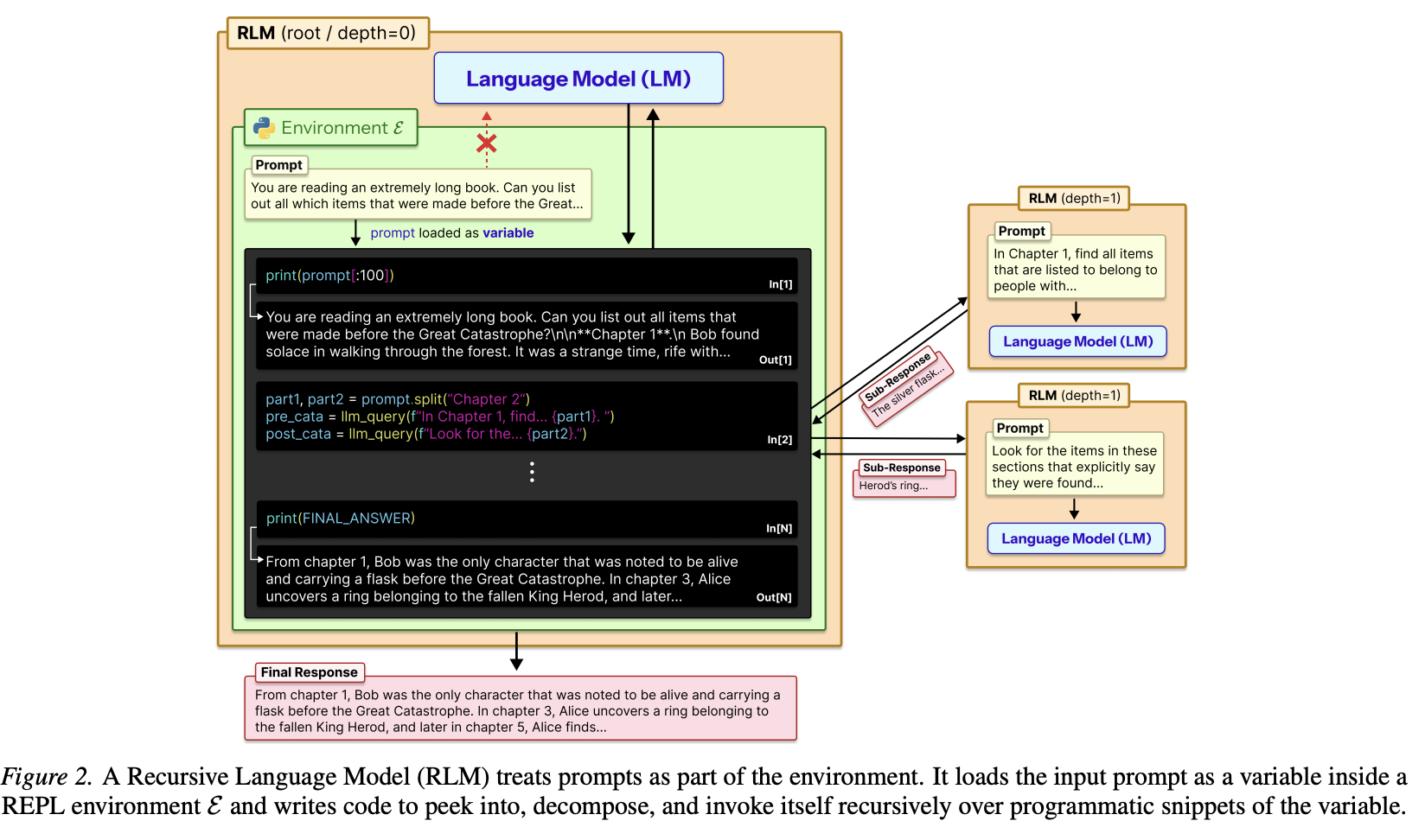
如图 2 所示,RLM 与 LLM 或推理模型提供相同的外部接口:它接受任意结构的字符串提示,并生成字符串响应。给定提示 ,RLM 初始化一个 Read-Eval-Print Loop (REPL) 编程环境,并将 设置为其中的一个变量的值。然后,它向 LLM 提供关于 REPL 环境的一般上下文信息(例如,字符串 的长度),并允许 LLM 编写代码来查看和分解 ,并迭代地观察执行过程中产生的任何副作用。至关重要的是,RLM 鼓励 LLM 通过编写符号程序来理解、转换和执行输入提示,这些符号程序会根据需要对输入进行多次切片调用 LLM 自身。
通过将提示本身视为外部对象并启用符号递归,RLM 解决了近期编码 Agent、检索 Agent和子 Agent 委托研究中表达能力的局限性。具体而言,以往的编码 Agent 和检索 Agent 将指定的外部数据源(例如文件系统或搜索文档库)视为获取片段的环境。然而,它们只能在崩溃之前用片段填充底层 LLM 的上下文窗口。类似地,以往的自委托方法允许 LLM 将自身作为子 Agent 调用。然而,由于它们被设计为以自回归的方式表达子调用,而不是以编程方式生成子调用,因此受到底层 LLM 输出长度的限制。
我们使用前沿闭源模型(GPT5)和前沿开源模型(Qwen3-Coder-480B-A35B)在四个复杂度各异的任务中评估 RLM:深度研究、信息聚合、代码库理解以及一项即使是前沿模型也会彻底失败的合成成对推理任务。我们将 RLM 与直接调用 LLM 以及上下文压缩 Agent、检索工具使用 Agent 和代码生成 Agent 进行比较。
我们发现,即使在超过 1000 万个 token 的规模下,RLM 也表现出极强的性能,并且在长上下文处理方面显著优于所有其他方法,在许多情况下,性能提升可达两位数百分比,同时成本却相近。尤其如图 1 所示,RLM 在处理更长的上下文和更复杂的任务时,性能下降的程度要小得多。
最后,我们小规模地对首个原生递归语言模型进行了后训练,结果表明,递归语言模型(RLM)只需少量额外训练即可快速改进。尽管小型开源模型(Qwen3-8B)即使在 RLM 框架下也难以解决长上下文任务,但我们提出的简单通用训练方案仅使用来自不相关领域的 1000 个样本,即可在四个评估任务中将其性能平均提升 28.3%。
2.Recursive Language Models

给定一个具有最大上下文大小 的基础神经语言模型 ,递归语言模型 (RLM) 是围绕 构建的推理时框架,它将用户提示视为环境的一部分,同时又不放弃通过多次调用 来密集处理其内容的能力。给定一个任意长度的提示字符串 ,RLM 与持久化的外部环境 交互,并返回一个响应字符串 (图 2)。我们希望实现:
- 1)几乎无限制的输入 token 数 ();
- 2)无限制的输出 token 数以及
- 3)无限制的语义范围,例如,能够执行 或 的语义工作。
算法 1 描述了 RLM 如何实现这一目标。给定一个提示符 ,RLM 初始化一个持久化的 REPL 编程环境,其中包含一个变量,该变量存储用户提示符字符串和一个用于调用子 RLM 并传入新提示符的函数。然后,它启动 RLM 循环。在第一次迭代中,该算法仅使用关于用户提示符的元数据(例如提示符的长度、短前缀以及如何访问提示符的各个部分)来调用根神经网络模型 。
通过提示(附录 C)和/或微调(附录 A),根节点被指示像 RLM 一样运行:也就是说,生成代码以帮助其理解和转换提示 的各个部分,并将中间值和最终响应构建成新的变量,这可能需要通过在循环中调用子 RLM 来实现。在第 4 节中,我们发现现有的 LLM 可以被提示执行此操作,并且训练一个 8B 模型使其具有原生递归能力是很有前景的。
RLM 循环的每次迭代都会在 REPL 中执行代码,更新 REPL 状态(中间变量),并将所有打印的文本收集到标准输出 (stdout) 中。只有关于标准输出的元数据,例如短前缀和长度,会被添加到 的历史记录中,以供下一次迭代使用。(这一点至关重要:它迫使 依赖变量和子调用来管理长字符串,而不是污染其窗口。原则上,如果我们把每次迭代限制为 个 token,那么最多会有 次根迭代,每次迭代都可以启动任意数量的子调用。这并非根本性的限制,例如,可以将根范围本身移到一个变量中,但我们通常希望限制任何递归级别的迭代次数。)一旦 RLM 在 REPL 中设置了变量 ,迭代就会停止,并将 中的值作为响应返回。
RLM 做出了现有 scaffolds 所缺乏的三个简单的设计选择。为了突出这些选择,我们引入算法 2 来说明一个看似“相似”但表达能力远逊于 RLM 的算法。这两个算法都支持子调用、外部对象和代码执行的概念,但它们在提示值和中间值的位置以及递归发生的位置上有所不同。
1)首先,RLM 必须为底层 LLM 提供一个指向用户提示 的符号句柄,以便模型无需将文本复制到根上下文窗口即可对其进行操作。然而,低效的算法 2 首先将用户提示 放入 LLM 上下文窗口(hist)中,从而继承了 的窗口限制,并回退到上下文压缩等启发式方法。即使 scaffolds 可以通过搜索操作或文件系统访问等方式访问外部数据,它在用户输入方面仍然受到致命的限制。
2)其次,低效的算法 2 要求 通过 动作直接自回归地生成输出。这看似无害,但实际上也意味着它无法生成超出 M 上下文窗口长度的输出。
3)第三,或许也是最重要的一点,RLM 需要符号递归。也就是说,在 中运行的代码必须能够对 进行程序化构造的转换(例如,在任意大的循环中),并调用 ,同时以符号化的方式存储中间结果。虽然算法 2 分别包含了代码执行动作和“子 LLM”动作,但它无法以程序化的方式调用子 LLM,因此只能委托一些明确描述的任务,而无法编写能够遍历提示符切片并启动 甚至 进程来理解或转换 的所有部分的简短程序。
3.Scaling Long Context Tasks
我们假设,LLM 的有效上下文窗口不能脱离具体任务而独立理解。也就是说,更“复杂”的问题即使在提示长度更短的情况下也会表现出性能下降。因此,我们必须根据任务复杂度随提示长度的变化情况来描述任务。
例如,大海捞针(NIAH)问题通常在提示长度增加时保持“针”的大小不变。因此,前沿模型现在可以在 RULER 任务中可靠地解决 100 万个 token 以上的提示问题,但在 OOLONG 任务中,即使提示长度远小于此,模型也会遇到困难。OOLONG 任务的答案几乎完全取决于提示中的每一行。(这有助于解释前面图 1 中观察到的模式:GPT-5 在 S-NIAH 任务中表现出良好的扩展性,因为即使提示长度增加,“针”的大小也保持不变;但在复杂度为线性的 OOLONG 任务和复杂度为二次的 OOLONG-Pairs 任务中,随着上下文长度的缩短,GPT-5 的性能下降速度加快。)
3.1 Tasks
我们围绕可以改变提示长度的任务来设计评估,这样我们就可以考虑那些难度随上下文长度变化而变化的问题。
S-NIAH。继 RULER 中的“大海捞针”任务之后,我们考虑一组包含 50 个独立任务的集合,这些任务要求在大量不相关的文本中查找特定的短语或数字。这里,所查找的信息量与输入长度的关系为 。
BrowseComp-Plus (1K documents)。这是一个针对 DeepResearch 问题的多跳问答基准测试,要求对多个不同文档进行推理。该基准测试提供了一个经过验证的离线语料库,保证每个问题都包含 golden 文档、证据文档和强否定文档。我们参考 Sun et al. (2025) 的方法,使用 150 个随机抽取的实例作为评估集;并提供 1000 个随机选择的文档作为输入,保证其中包含 golden 文档和证据文档。我们报告正确答案的百分比。每个任务的答案都需要整合来自多个文档的信息,这使得该测试比 S-NIAH 更难,尽管它们所需的文档数量相同。
OOLONG。这是一个耗时较长的推理基准测试,需要对输入数据进行语义转换,然后将这些转换后的片段聚合起来形成最终答案。我们基于原始论文中的评分方法进行报告,其中数值答案的评分标准为 ,其他答案则采用完全匹配的方式。我们重点关注 trec_coarse 测试集,该测试集包含 50 个任务,任务数据集包含带有语义标签的问题。每个任务都需要使用数据集中的几乎所有条目,因此其处理复杂度与输入长度呈线性关系。
OOLONG-Pairs。我们对 OOLONG 数据集的 trec_coarse 划分进行了修改,新增了 20 个 query,这些 query 需要聚合成对的数据块来构建最终答案。我们报告了答案的 F1 分数。每个任务都需要使用数据集中几乎所有的条目对,因此需要处理的条目数量相对于输入长度呈平方级增长。附录 D.1 中提供了此基准测试中的所有查询。
LongBench-v2 CodeQA。这是一道基于 LongBench-v2 的多选择代码库理解题,对现代前沿模型来说极具挑战性。我们以正确答案的百分比来报告得分。每道题都需要对代码库中固定数量的文件进行推理,才能找到正确答案。
3.2 Methods and Baselines
我们使用两种现代语言模型(GPT-5,中等推理能力和默认采样参数)以及 Qwen3-Coder-480B-A35B(采样参数采用 Qwen Team (2025b) 中描述的方法)将 RLM 与常用的任务无关推理方法进行比较。对于 Qwen3-Coder-480B-A35B,我们基于计算提供商 Fireworks 计算成本。除了评估基础模型在所有任务上的表现外,我们还评估了以下方法和基线模型:
CodeAct (+ BM25)。我们直接将本文提出的 RLM 与 CodeAct 智能体进行比较,该智能体能够在 ReAct环中执行代码。与 RLM 不同,CodeAct 不会将用户提示卸载到代码环境中,而是直接将其提供给 LM。此外,我们参考 Jimenez et al. (2024) 和 Chen et al. (2025) 的研究,为该智能体配备了 BM25 检索器,用于索引适合使用检索器的任务的输入上下文。
CodeAct with sub-calls。为了彻底消除在 REPL 中将上下文作为变量卸载的做法,我们评估了一个能够调用子 LM 函数的 CodeAct 基线模型。与 RLM 相比,这种方法直接将上下文加载到模型中。
Summary agent。
RLM with REPL。
RLM with REPL, no sub-calls。我们提供了一种方法的消融,其中提示符加载在 REPL 环境中,但无法执行子 LLM 调用。
Finetuning。
4.Results and Discussion